
KVCache and Prefill phase in LLMs
Published:
Simple explanation of KVCache and Prefill phase in LLMs
The Inference
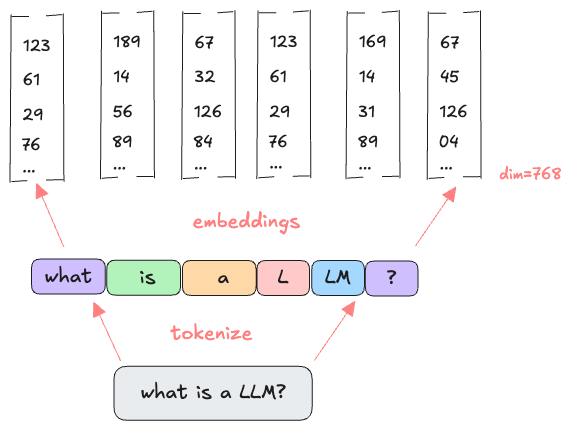
- The initial sentence “what is a LLM?” is tokenized ((also commonly referred as context + user prompt))
- Each token is converted to embeddings of dimension 768 (GPT-2 for example).
- Forwarded to the transformer block to Contextualize the embeddings
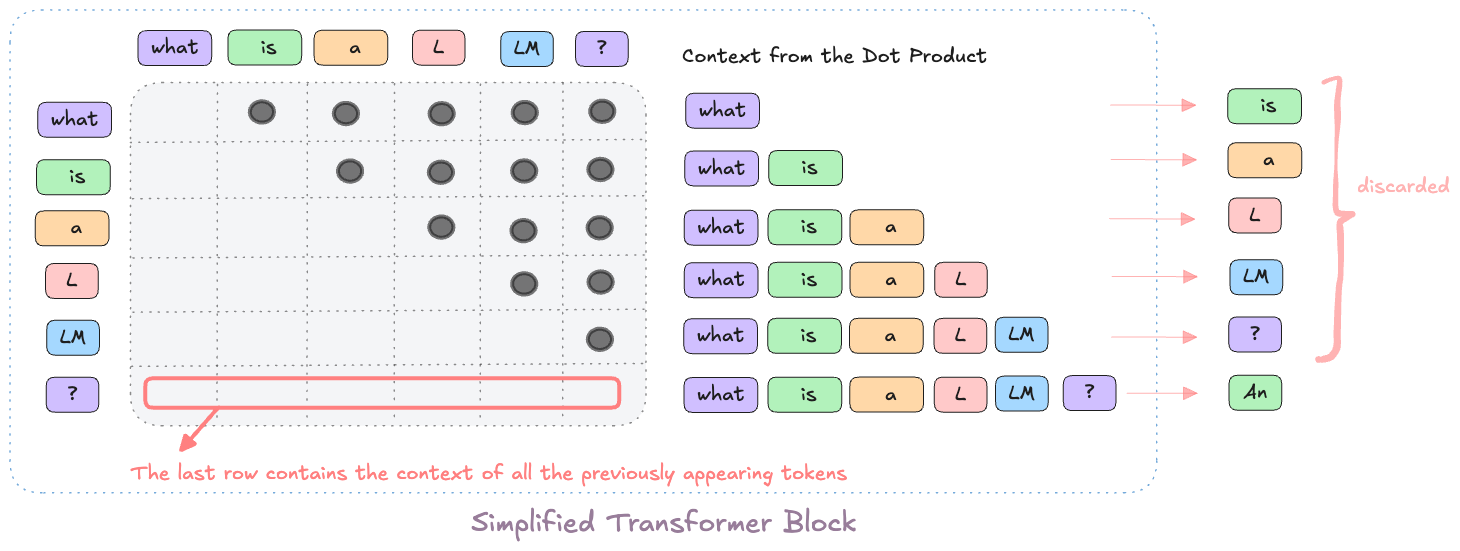
The Problem
During Inference the attention block needs to compute a scaled dot product of the Queries, Keys and Values
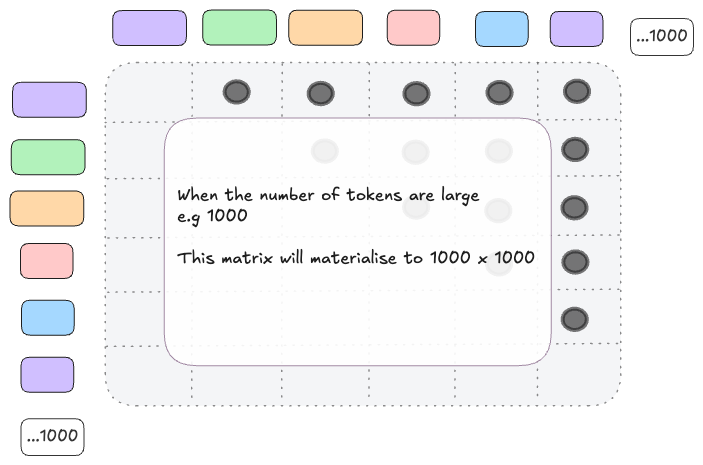
📔: Materialise is a fancy way of saying that you need to allocate memory for a Tensor of 1000x1000 with each dimension being 768 🙂
Enter KVCache
- The trick is to identify what is important in each timestep of the decoding phase (i.e the Inference) Turns out only the last token forwarded to the Attention block contains the context of all previous tokens We sure can exploit this
- Use a list datastructure to store previous timestep states
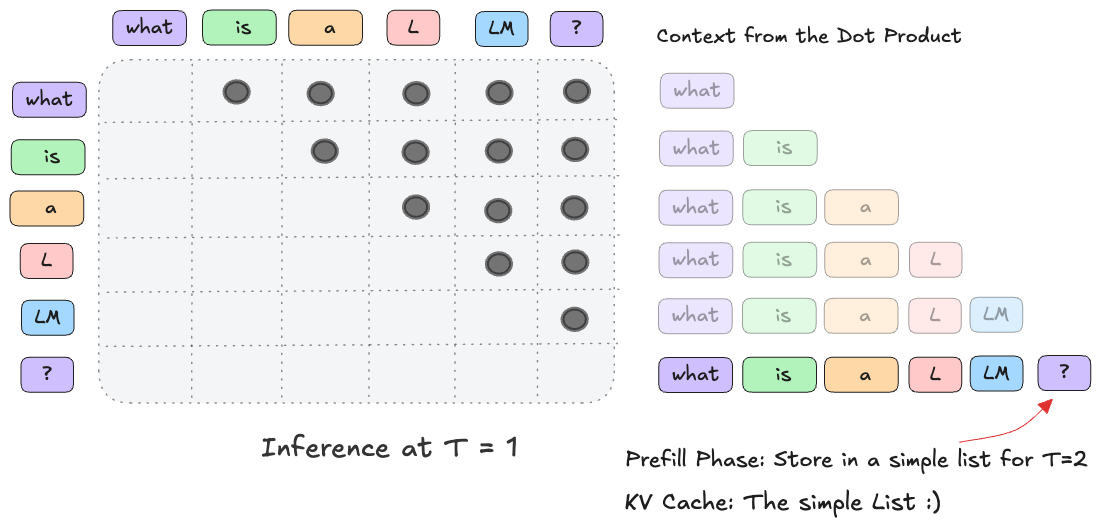
What is Prefill Phase
- This is the first step of Inference at T=1 ( T>1 is the decoding phase )
- All of the input (context + prompt) is forwarded to the Model
- Unlike the Decoding phase there is no “for loop”
Prefill Phase
Transformer is sequence to sequence model. In simple terms it means, if 6 words are forwarded to the Model. The model will output 6 next words as shown below.
Adding to the Cache
# concatenate to list
self.key_cache[layer_idx] = torch.cat([self.key_cache[layer_idx], key_states], dim=-2)
self.value_cache[layer_idx] = torch.cat([self.value_cache[layer_idx], value_states], dim=-2)
Using the Cache
key_states = key_states.view(bsz, q-len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
if kv_cache is not None:
# if the list is present then concatenate to it and use that whole list
key_states, value_states = kv_cache.update(keys_states, value_states, self.layer_idx)